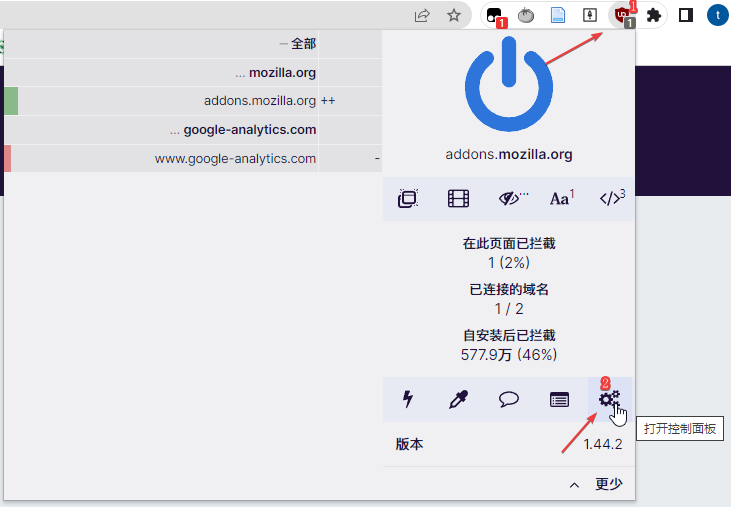
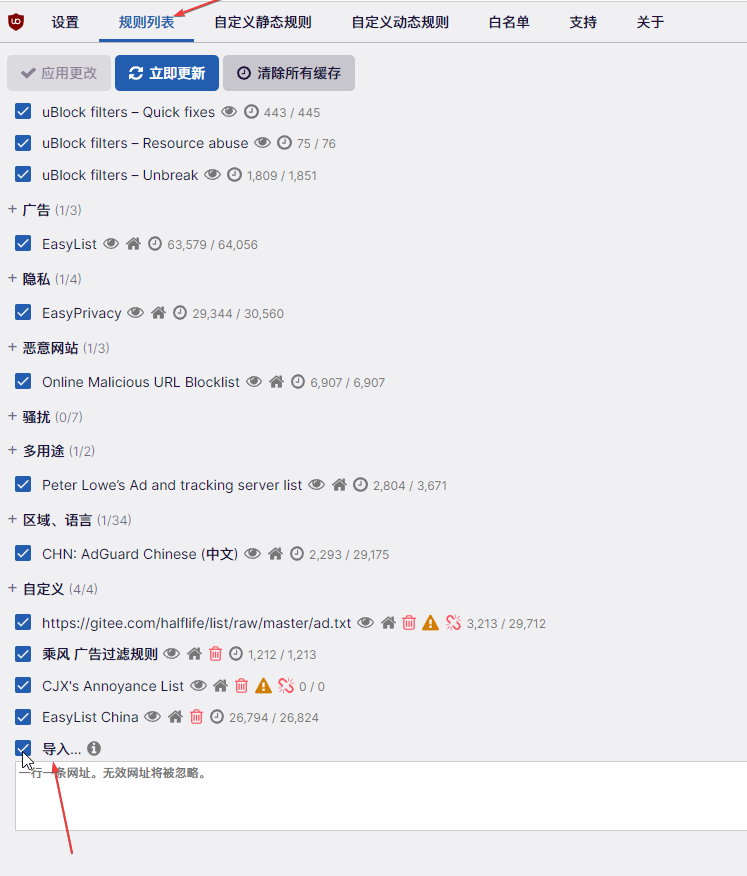
添加常用规则,这里提供几个链接
https://raw.githubusercontent.com/easylist/easylistchina/master/easylistchina.txt
https://raw.githubusercontent.com/cjx82630/cjxlist/master/cjx-ublock.txt
这样就成功啦!
我们现在测试一下广告屏蔽的效果
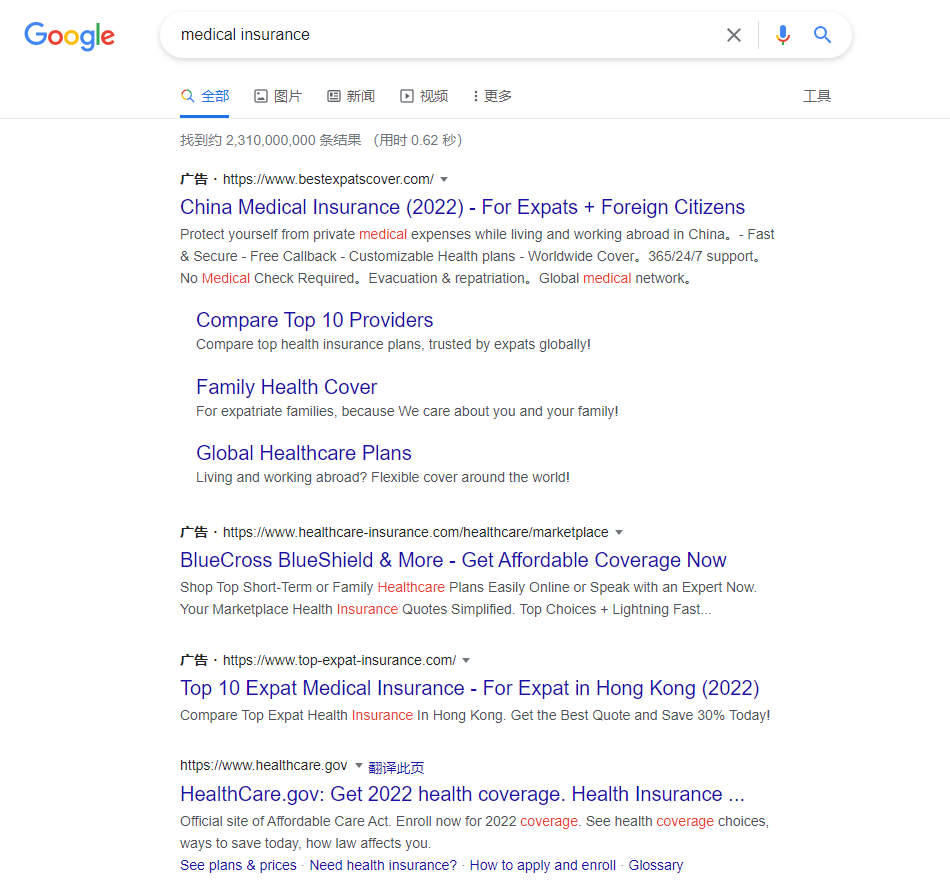
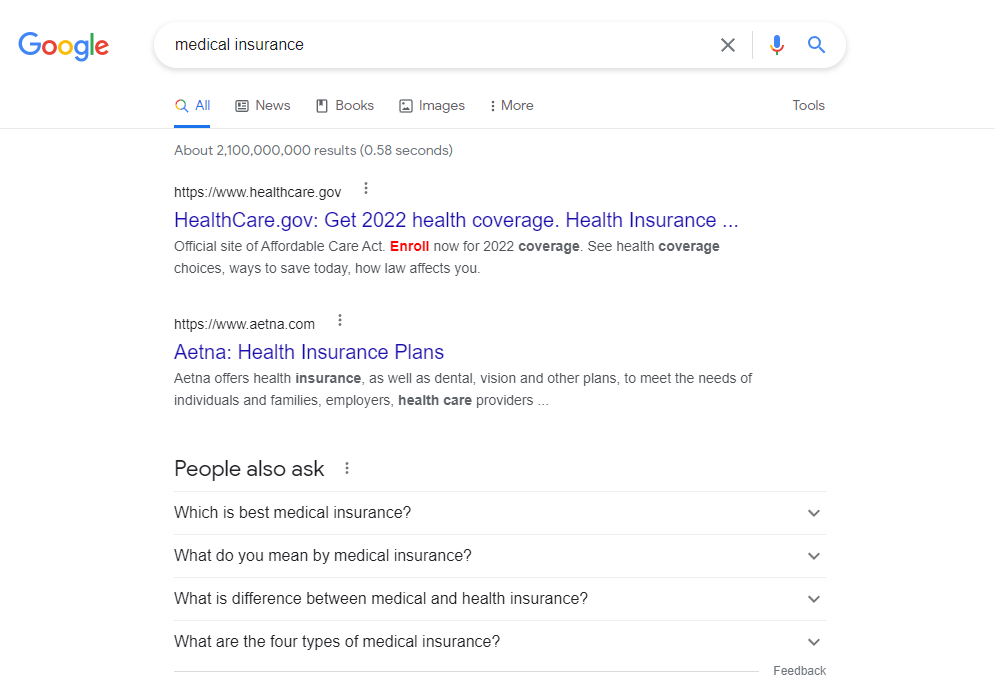
亲测各大视频网站的片头广告也被去除了!
Enjoy :)
]]>大模型的发展历程是什么?
我以为自己需要的是一张时间表。哪一年出现 Transformer,哪一年出现 GPT-3,哪一年 ChatGPT 火了,哪一年 GPT-4 开始支持多模态,哪一年 DeepSeek 又被大家讨论。
但问着问着我发现,时间线只能告诉我“发生了什么”,不能告诉我“我为什么不懂”。
我真正卡住的地方不是某个模型在哪一年发布,也不是某个模型有多少参数。我真正卡住的是:这些名字背后到底有什么关系?为什么它们都叫大模型?为什么大家反复提 Transformer?MoE 是不是一种新架构?FFN 为什么和模型的“记忆”有关?CLIP 和 SAM 又为什么会出现在多模态大模型的讨论里?
也就是说,我一开始以为自己在问大模型历史,后来才发现自己其实是在问:
我该如何建立一套能放下这些概念的知识结构?
这篇文章就是我给自己的答案。它不是论文综述,也不是百科词条,而是一份学习地图:以后我忘了某个概念,可以回到这里,先找到它在整张图里的位置。
大模型的发展很容易写成流水账:
深度学习兴起
-> Transformer 出现
-> BERT / GPT 开启预训练时代
-> GPT-3 展示规模化能力
-> ChatGPT 让对话式 AI 出圈
-> GPT-4 / GPT-4o 推动多模态
-> DeepSeek 等模型让效率、成本和推理能力成为焦点
这些节点当然重要。但如果只记年份,我还是不知道大模型为什么会变强。
后来我把时间线压缩成几次关键变化:
| 变化 | 我真正要记住的东西 |
|---|---|
| 从手工规则到数据学习 | 能力不是一条条规则写进去的,而是模型从大量数据里学出来的 |
| Transformer 出现 | 大规模语言模型有了一个非常重要的架构底座 |
| 预训练成为主流 | 模型先学通用语言能力,再适配具体任务 |
| 规模化能力显现 | 模型开始从专用工具变成通用接口 |
| ChatGPT 出圈 | 对话界面改变了普通人调用 AI 的方式 |
| 多模态发展 | 模型不再只处理文字,而开始处理图像、音频等信息 |
| 架构效率竞争 | 继续变大之外,成本、推理、长上下文和部署效率也变得关键 |
所以,大模型发展史对我来说不是“模型排行榜”,而是一条能力扩展路线:
数据学习
-> 可扩展架构
-> 预训练
-> 规模化
-> 对话交互
-> 多模态
-> 推理与效率
我一开始很容易把 Transformer、GPT、大模型混在一起,仿佛它们说的是同一件事。
后来我才意识到,Transformer 更像一个底座。在这个底座上,长出了几条不同路线。
Transformer
|
|-- Encoder-only
| |-- BERT
| |-- 偏理解:分类、检索、抽取、语义匹配
|
|-- Decoder-only
| |-- GPT
| |-- LLaMA
| |-- DeepSeek
| |-- 偏生成:对话、写作、代码、推理
|
|-- Encoder-Decoder
|-- T5
|-- BART
|-- 一些翻译、摘要、OCR、跨模态转换任务
这张家谱树对我很重要。
BERT 和 GPT 都是 Transformer 路线,但它们不是同一种用法。BERT 更像理解器,擅长看完整上下文后做判断。GPT 更像生成器,按顺序预测下一个 Token。T5、BART 这类 Encoder-Decoder 模型,则更像把一种输入转换成另一种输出。
今天很多对话大模型走的是 Decoder-only 路线,因为对话、写作、代码生成,本质上都可以被组织成“根据前文继续生成下一个 Token”的任务。
这也解释了一个常见误会:
Transformer 不是 GPT。GPT 是 Transformer 家族里 Decoder-only 这一支的代表。
知道模型家谱还不够。我还想知道:我输入一句话以后,模型内部到底发生了什么?
一个简化的数据流是这样的:
输入文字
-> Tokenizer
-> Token IDs
-> Embedding
-> 多层 Transformer Block
-> RMSNorm / LayerNorm
-> Attention
-> 残差连接
-> RMSNorm / LayerNorm
-> FFN / MoE
-> 残差连接
-> Final Norm
-> LM Head
-> Softmax
-> 下一个 Token
这里每个词都有位置。
Tokenizer 负责把文字切成 Token。模型不直接处理自然语言,而是处理 Token 对应的编号。现代分词常见思路之一是 BPE:从更小的字节或字符片段开始,逐步合并高频片段。这样做的好处是,即使遇到生僻词,也可以拆成更小单位,不至于完全不认识。
Embedding 负责把 Token ID 变成向量。编号本身没有语义距离,向量才是后续计算真正处理的对象。
Attention 负责让 Token 之间互相看见。比如一句话里“它”指代什么,需要看上下文;Attention 就是在处理这种上下文关系。
残差连接负责把原始输入加回来。它像是保留底稿,再叠加每一层的新处理结果,避免深层网络里信息和梯度传不下去。
RMSNorm 或 LayerNorm 负责稳定数值。RMSNorm 可以理解成“稳压器”或“音量调节器”:它不负责产生知识,但能让向量的数值幅度保持在比较稳定的范围里,避免层数深了以后数值越来越大或越来越小。
LM Head 负责把模型内部向量映射回词表。Softmax 再把分数变成概率,模型据此选择或采样下一个 Token。
所以,语言模型生成一段话,本质上是在循环做一件事:
根据已有上下文
-> 预测下一个 Token
-> 把新 Token 拼回上下文
-> 再预测下一个 Token
在 Transformer Block 里,Attention 很容易吸引注意力,因为它名字响亮,也确实重要。
但我后来发现,FFN 同样关键。
一个典型 FFN 可以粗略理解成:
输入向量
-> 升维
-> 激活函数
-> 降维
-> 输出向量
Attention 更像信息调度:当前 Token 应该参考哪些上下文?哪些位置的信息更重要?
FFN 更像深度加工:拿到上下文信息后,当前这个向量应该触发什么模式?哪些语义、事实、风格、输出倾向应该被激活?
有研究把 Transformer 的 FFN 层解释成一种 Key-Value Memory。这个说法对我很有帮助,因为它让我理解了模型“记住知识”的方式。
模型不是像数据库一样存:
key: 法国首都
value: 巴黎
它更像是在训练过程中,把大量文本模式压缩进参数里。生成时,当前上下文会激活某些参数模式,从而影响下一个 Token 的概率。
所以“模型记住了知识”这句话要谨慎理解。它不是查表,而是在高维参数空间里做概率计算。这也解释了为什么模型既能答对很多事实,也会产生看起来合理但实际错误的幻觉。
理解 FFN 之后,MoE 就容易理解很多。
MoE 的英文是 Mixture of Experts,中文常叫混合专家模型。但这个翻译本身并不能让我理解它。
真正有用的理解是:
MoE 通常不是推翻 Transformer,而是改造 Transformer 里的 FFN 部分。
普通 FFN 是每个 Token 都走同一套前馈网络:
Token 向量
-> 一个 FFN
-> 输出
MoE 则是把 FFN 拆成很多专家:
Token 向量
-> Router
-> 选择少数专家 FFN
-> 合并专家输出
这里有两个概念一定要分清:
总参数:模型一共有多少参数
激活参数:处理一个 Token 时实际参与计算的参数
MoE 的核心价值在于,它可以让模型拥有很大的总容量,但每次只激活一部分参数。这样模型不是“免费变强”,而是在容量和计算成本之间做了新的权衡。
当然,MoE 也会带来新问题:Router 怎么训练?专家负载是否均衡?不同设备之间通信成本如何控制?专家是否真的学出了不同能力?这些都不是“多放几个专家”就能自动解决的。
DeepSeek-V3 是一个很适合用来串联这些概念的案例。
根据 DeepSeek-V3 Technical Report,它是一个基于 Transformer 的 MoE 语言模型,总参数约 671B,每个 Token 激活约 37B 参数,训练数据约 14.8T tokens,支持 128K 上下文。它的几个关键词包括 Decoder-only、DeepSeekMoE、MLA、RMSNorm、RoPE、FP8 混合精度、DualPipe 等。
这些词如果单独看,会很散。但放进数据流里就清楚了:
输入文字
-> Tokenizer
-> Embedding
-> 多层 Decoder-only Transformer Block
-> RMSNorm:稳定数值
-> MLA:处理注意力,同时压缩 KV Cache 成本
-> 残差连接:保留原始信息
-> RMSNorm
-> DeepSeekMoE:Router 选择专家,稀疏激活 FFN
-> 残差连接
-> Final RMSNorm
-> LM Head
-> Softmax
-> 下一个 Token
MLA 和 MoE 不是一回事。
MLA 是注意力机制上的优化,核心目标之一是减少长上下文推理时 KV Cache 的压力。
MoE 是 FFN 路径上的稀疏化改造,核心目标是扩大模型总容量,同时控制每个 Token 实际激活的计算量。
这也是我理解 DeepSeek-V3 的关键:它不是“一个神秘的新模型”,而是把现代大模型里的几个重要方向组合在了一起。
Decoder-only Transformer
+ MLA 注意力优化
+ MoE 稀疏专家
+ 低精度训练和并行工程
+ 长上下文支持
对话记录里还提到了一条很重要的线:注意力机制本身也在演化。
最原始、最经典的是 MHA,也就是 Multi-Head Attention。它让模型用多个注意力头从不同角度看上下文。
后来出现了 MQA、GQA 等做法,目标之一是减少 Key / Value 的缓存和计算成本。再后来,DeepSeek-V3 这类模型把 MLA 推到很显眼的位置,通过潜在向量压缩 Key / Value 表示,进一步降低长上下文推理压力。
还有一些路线会尝试稀疏注意力、线性注意力、滑动窗口注意力等,目标都是面对同一个问题:
上下文越长,注意力越贵,KV Cache 越重。
我现在不会把这些名字都背下来,而是把它们放到同一个问题下面:
如何让模型在更长上下文里,仍然算得动、存得下、跑得快?
这比单独记 MHA、GQA、MLA、Sparse Attention 更有用。
我一开始以为,多模态大模型就是“模型会看图”。
后来发现这句话太粗糙。
“看图”至少可以拆成两个问题:
这张图表达了什么语义?
图里的东西具体在哪里?
CLIP 更接近解决第一个问题。
CLIP 的核心是图文语义对齐。它把图像和文本放到相近的语义空间里,让模型能判断一张图和一句话是否匹配。它很适合理解“这张图大概是什么”“这段文字和这张图是否对应”。
SAM 更接近解决第二个问题。
SAM 的核心是图像分割。它擅长把图里的目标区域分出来,回答“这个东西在哪里”。但它本身不一定告诉你这个区域在语义上是什么。
所以我现在这样记:
CLIP:更像知道“这是什么”
SAM:更像知道“在哪里”
当然,这只是帮助理解的简化说法。严格讲,CLIP 做的是图文对齐,SAM 做的是分割提示下的视觉区域提取。
多模态大模型要做的事情,是把这些视觉能力和语言模型接起来。
一种常见路线是拼接式:
图像
-> 视觉编码器
-> 投影器
-> 语言模型
-> 文本回答
视觉编码器负责把图片变成视觉特征。投影器负责把视觉特征转换到语言模型能接收的表示空间。语言模型再基于这些视觉信息进行回答、推理或生成。
另一种路线更强调原生多模态,把文本、图像、音频甚至视频统一成更一致的表示,让不同模态更深地进入同一套推理流程。GPT-4o 这类模型让我意识到,多模态不是简单多一个输入框,而是模型感知和表达世界的边界被扩展了。
对话里还提到 DeepSeek-OCR 这类思路:把文本渲染成图像,通过视觉编码进行信息压缩,再交给解码器处理。这让我看到一个有意思的方向:多模态不只是“看图片”,也可能成为信息压缩和跨模态转换的新工具。
我一开始也容易忽略训练流程。
大模型不是预训练完就自然变成 ChatGPT。一个粗略流程是:
预训练
-> SFT 监督微调
-> 对齐训练
-> 安全、风格和工具使用能力调整
预训练让模型学会语言和世界中的大量统计模式。SFT 让模型学会按照指令回答。对齐训练则让模型更接近人类偏好,比如更有帮助、更安全、更符合对话习惯。
对话里出现了 PPO、DPO、GRPO 这些词,我现在先把它们放在地图上:
PPO 是一种强化学习式的对齐方法。典型 RLHF 流程里会出现策略模型、参考模型、奖励模型、价值模型等角色。它比较复杂,但曾经是对齐训练里非常重要的路线。
DPO 更直接。它利用“哪个回答更好”的偏好数据,让模型直接学习偏好差异,不一定显式训练奖励模型。
GRPO 则常被放在推理、数学、代码等任务讨论里。它的直觉是让同一组候选答案内部比较,用组内相对表现来提供训练信号。
这一块我还没有完全吃透,但我现在至少知道它们属于哪一层:
模型架构:Transformer / MoE / Attention
训练阶段:预训练 / SFT / PPO / DPO / GRPO
产品表现:对话质量 / 安全性 / 推理能力 / 工具使用
不能把它们混在一起。
如果只看模型架构,还是不完整。
真正把大模型跑起来,还会遇到工程工具链。
DeepSpeed 主要解决大模型分布式训练的问题,典型关键词是 ZeRO 等内存优化技术。
vLLM 主要解决高并发推理服务的问题,典型关键词是 PagedAttention。
Safetensors 是 Hugging Face 生态里常见的安全、快速的模型权重存储格式。
MLX 是 Apple Silicon 上本地推理和机器学习计算相关的工具链。
Hugging Face 模型仓库里常见几个文件:
config.json
-> 模型结构配置,比如层数、隐藏维度、注意力头数
*.safetensors
-> 模型权重,也就是训练出来的参数
tokenizer.json
-> 分词器配置,包括词表和切分规则
README.md
-> 模型卡,说明模型用途、训练信息、限制和许可证
这让我意识到,“一个模型”不只是一个抽象名字。真正落地时,它会变成配置、权重、分词器、推理框架、部署服务、显存管理和 API 成本。
对话里还问过 MiniMax、GLM、DeepSeek 这些模型架构有没有区别。
这类问题很容易变成参数表,但参数表很快会过期。具体版本、价格、上下文长度、指标排名都需要查最新官方资料,不能靠聊天记录里的二手信息直接写死。
但比较框架可以保留下来。
以后我看到一个新模型,会先问:
| 维度 | 我应该问什么 |
|---|---|
| 基础架构 | 是 Encoder-only、Decoder-only,还是 Encoder-Decoder? |
| 参数结构 | 是 Dense 还是 MoE?总参数和激活参数分别是多少? |
| 注意力机制 | 用 MHA、GQA、MLA、稀疏注意力,还是线性注意力? |
| 上下文能力 | 标称上下文多长?长上下文真实效果如何? |
| 多模态能力 | 支持哪些输入输出?是拼接式还是更原生的融合? |
| 训练方式 | 预训练、SFT、偏好对齐、推理强化分别怎么做? |
| 工程效率 | 推理成本、延迟、吞吐、显存占用如何? |
| 开放程度 | 是否开源?是否有模型卡、权重、推理代码? |
这比单纯问“哪个模型更强”有用。
因为模型强不强,往往取决于场景。写作、代码、数学、长文档、多模态、本地部署、低成本 API,关注点都不一样。
整理到最后,我真正需要的是这样一张地图:
大模型知识结构
|
|-- 发展脉络
| |-- 数据学习
| |-- Transformer
| |-- 预训练
| |-- 规模化
| |-- 对话交互
| |-- 多模态
| |-- 推理与效率
|
|-- Transformer 家族
| |-- Encoder-only:BERT
| |-- Decoder-only:GPT / LLaMA / DeepSeek
| |-- Encoder-Decoder:T5 / BART / OCR 和转换类任务
|
|-- 模型内部数据流
| |-- Tokenizer / BPE
| |-- Embedding
| |-- Attention
| |-- FFN
| |-- RMSNorm / LayerNorm
| |-- Residual
| |-- LM Head / Softmax
|
|-- 架构优化
| |-- MHA / GQA / MLA
| |-- KV Cache
| |-- MoE / Router / Experts
| |-- RoPE
| |-- Dense vs Sparse
|
|-- 现代模型案例
| |-- DeepSeek-V3
| |-- DeepSeekMoE
| |-- MLA
| |-- FP8 / DualPipe
|
|-- 视觉和多模态
| |-- CLIP:图文语义对齐
| |-- SAM:图像分割
| |-- 视觉编码器
| |-- 投影器
| |-- 多模态 LLM
| |-- DeepSeek-OCR 这类跨模态压缩思路
|
|-- 训练和对齐
| |-- 预训练
| |-- SFT
| |-- PPO
| |-- DPO
| |-- GRPO
|
|-- 工程落地
|-- DeepSpeed
|-- vLLM
|-- Safetensors
|-- MLX
|-- Hugging Face 仓库结构
|-- Tokenizer / config / weights
这张图不保证覆盖所有细节,但它解决了我最初的问题。
我以后再看到一个名词,可以先问:
它属于发展史、架构、数据流、训练、多模态,还是工程?
它在模型里哪个位置?
它解决什么问题?
它带来什么代价?
它和我已经知道的哪个概念相邻?
这比背定义更重要。
我写这篇文章,首先是写给自己看的。
因为我知道自己一定会忘。过一段时间,我可能又会忘记 MoE 和 FFN 的关系,忘记 RMSNorm 放在哪里,忘记 CLIP 和 SAM 的区别,忘记 DeepSeek-V3 的 MLA 到底优化什么,也忘记 PPO、DPO、GRPO 分别属于训练流程里的哪一段。
但没关系。
我不需要一次性记住所有名词。我只需要留下一条能回来的路。
这条路不是从定义开始,而是从问题开始:
我为什么会困惑?
这个概念在结构里的位置是什么?
它前后连接了哪些东西?
如果我忘了它,应该回到哪张图?
这也是我现在对学习技术概念最大的体会:
知识不是靠一次性记住所有定义建立起来的,而是靠不断给概念找到位置建立起来的。
这篇文章就是我给自己画下的第一张大模型地图。
npm install --save @types/leaflet
这行代码会自动下载Leaflet的TypeScript定义,并自动添加到packages.json文件中的dependency项。
安装之后重新启动VScode可以发现自动补全功能又出现了
]]>思想是这样的
import pandas as pd
import geopandas as gpd
# The code below is used to convert the csv file into a shapefile.
nameList = ['india&Pakistan91_95', 'india&Pakistan96_00', 'india&Pakistan01_05', 'india&Pakistan06_10', 'india&Pakistan11_15', 'india&Pakistan16_20']
for name in nameList:
csvpath = r"D:\Desktop\StuInnovate\data\GTD\筛选\{}.csv".format(name)
csvFile = pd.read_csv(csvpath)
csvFileCal = csvFile[['latitude', 'longitude','nkill','nwound','property','nhostkid']]
csvFileCal.fillna(0, inplace=True) #将NaN设置为0
csvFileCal['severeIndex'] = csvFileCal['nkill'] + csvFileCal['nwound'] + csvFileCal['property'] + csvFileCal['nhostkid']
csvFile['severeIndex'] = csvFileCal['severeIndex']
geoGDF = gpd.GeoDataFrame(csvFile, geometry=gpd.points_from_xy(csvFile.longitude, csvFile.latitude))
geoGDF.crs = {'init': 'epsg:4326'}
geoGDF.to_file(r"D:\Desktop\StuInnovate\data\GTD\shp\{}.shp".format(name), driver='ESRI Shapefile')
添加常用规则,这里提供几个链接
https://raw.githubusercontent.com/easylist/easylistchina/master/easylistchina.txt
https://raw.githubusercontent.com/cjx82630/cjxlist/master/cjx-ublock.txt
这样就成功啦!
我们现在测试一下广告屏蔽的效果
亲测各大视频网站的片头广告也被去除了!
Enjoy :)
]]> Jetbrains家的字体一直很赏心悦目,想在VS开发中也用到它;逛了逛官网,发现Jetbrains Mono font是开源的。
你可以在这个链接中下载。
在上面链接中下载字体,解压后选中你要安装的ttf文件,右键菜单栏中选择安装
打开 Visual studio 进入设置页面,将首页Windows渲染功能关闭
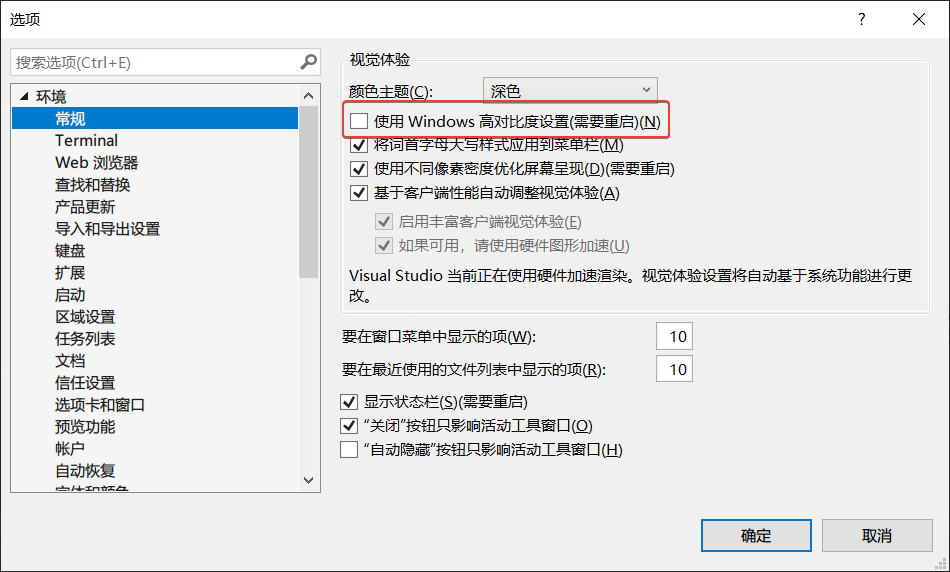
首先参考这篇博文
完成它的流程之后,需要注意的是,要在项目设置中修改
不要把dll都拷贝到目录下,右键项目-属性-调试-环境中依次加入dll所在的目录,比如:
PATH=E:\Development\QGIS_3.24.2\bin;E:\Development\QGIS_3.24.2\apps\Qt5\bin;E:\Development\QGIS_3.24.2\apps\qgis\bin;E:\Development\QGIS_3.24.2\share\gdal
注意:取消勾选 左下角的从父级或项目默认设置继承选项。
Debug folder?
$(SolutionDir)bin\$(Platform)\$(Configuration)\$(ProjectName)$(SolutionDir)bin\intermediates\$(Platform)\$(Configuration)\$(ProjectName)A pointer is just a integer which hold address!
a reference could be a other name of a variable
]]>

MIPS所采用的寄存器如上图所示,下面列出几个常用的寄存器
$zero 存储唯一值——0$a0-\$a3 这三个寄存器存储函数参数$t0-\$t7、$t8-\$t9 存储临时变量;注意这两组寄存器并不相连$s0-\$s7 用于保存变量的值$sp 保存栈指针;指向栈顶位置$ra 存储下一条需要执行指令的地址
算术运算
加法
add $Destination,$num1,$num2
上述等价于—> Destination = num1 +num2
减法
sub $Destination,$num1,$num2
上述等价于—> Destination = num1 - num2
加立即数immediate
addi $Destination,$num1,num2
num2是一个数字而非寄存器
📌注意!没有subi;subi可以用addi加负数代替
不检测溢出的加减法
addu $Destination,$num1,$num2
subu $Destination,$num1,$num2
Ada检测溢出、C不检测溢出
因此,编译器对于溢出的会按照语言的不同来转换不同的机器指令
addu和subu就是不检测溢出的指令
内存相关数据传送
LoadWord 从内存中加载一个字(通常是32位)
lw $t0,offset($s0)
表示从$s0指向的内存地址加offset偏移量后取得32位数据存入寄存器t0
此处的$s0实际上存储的是一个指针
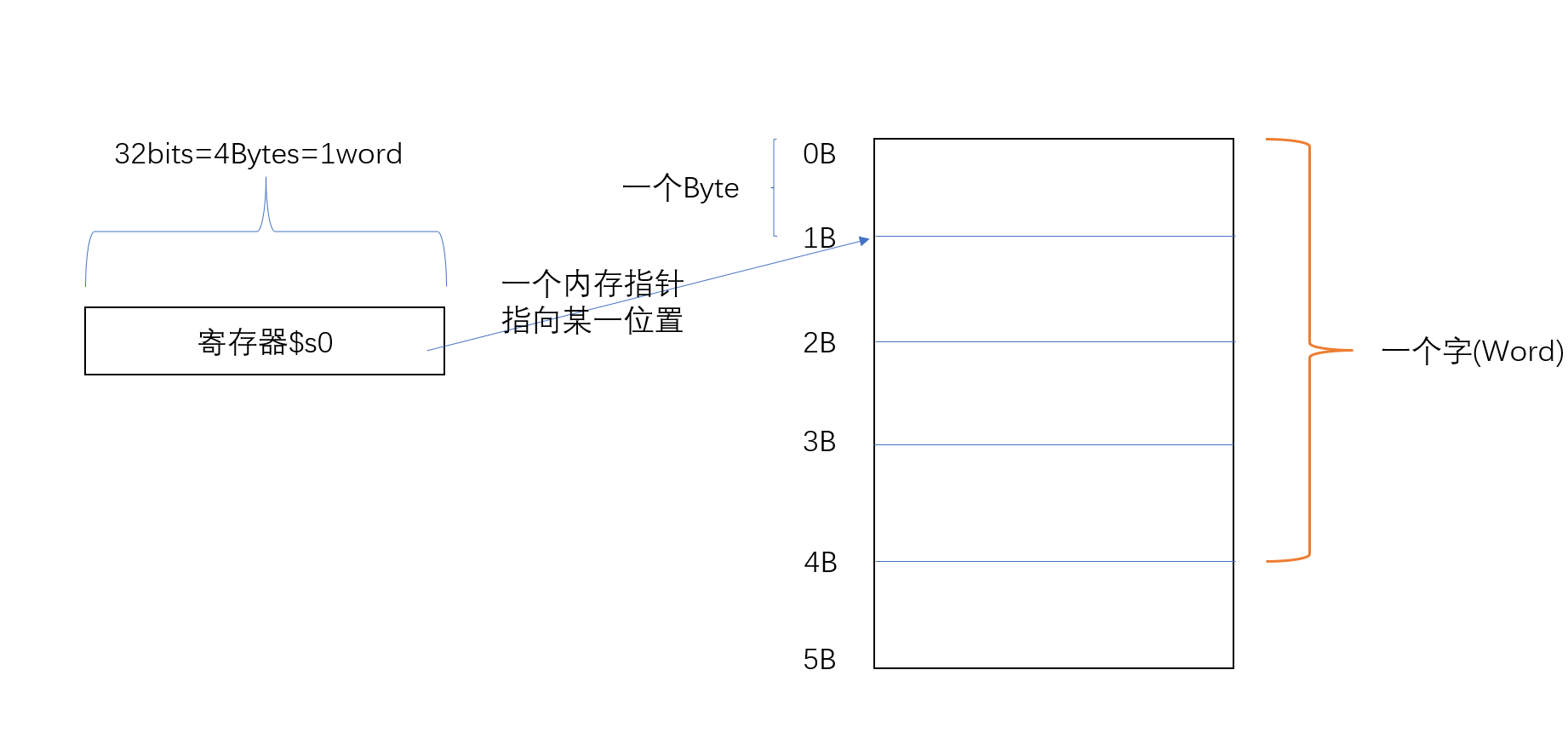
上图中内存指针指向1B;在1B的基础上+offset,以此为起始位置,取一个字放入$t0
StoreWord 向内存中存储一个字(通常是32位)
sw $t0,offset($s0)
和上图原理一致,只是方向相反,取$t0的值,在$0指向的内存地址上+offset作为起始地址存储一个Word
字对齐:相邻字之间的地址相差四个字节而不是一个字节
LoadByte
lb $s0,3($s1)
从$s1+3的地址开始取一个Byte的数据存入$s0
🤦♂️这里出现问题了,寄存器有4Byte,要存入1Byte怎么存放呢?
答案是将这8bits存到寄存器的低8位,高24位 符号位扩展
lbu LoadByteUnsighed;该指令会对高位进行零扩展StoreByte
sb $s0,3($s1)
从$s0中取一个Byte存入内存中$s1+3的位置
😶32位寄存器中取8位存入,那剩下的24位怎么办?
比较指令
相等
$beq $reg1,$reg2,Label
当 reg1==reg2 时跳转到 Label 处
不相等
$bne $reg1,$reg2,Label
当 reg1 != reg2 时跳转到 Label 处
无条件跳转
j Label
跳转到 label处
Set on less than;
slt reg1,reg2,reg3
使用这一条指令,可以实现
<、>、≤、≥的判断
小于
if (g<h) goto Less; #变量映射是 g:$s0,h:$s1
------------>
slt $t0,$s0,$s1
bne $t0,$0,Less大于等于
if (g≥h) goto GTE; #变量映射是 g:$s0,h:$s1
------------>
slt $t0,$s0,$s1
beq $t0,$0,GTE小于等于
if (g≤h) goto LTE; #变量映射是 g:$s0,h:$s1
------------>
slt $t0,$s1,$s0
beq $t0,$0,LTE大于
if (g>h) goto LTE; #变量映射是 g:$s0,h:$s1
------------>
slt $t0,$s1,$s0
bne $t0,$0,LTE👉还有立即数比较的
slti无符号比较的
sltu
跳转指令
Jump Regster 直接跳转寄存器
jr $reg
最常用的就是直接跳转到 $ra 即下一行要执行指令的位置
Jump and Link 跳转并保存
jal Label
逻辑运算
按位与运算
and $reg1,$reg2,$reg3
reg1=reg2®3
与立即数进行与运算
and $reg1,$reg2,immediate
reg1=reg2&immediate
⭐使用掩码做与运算将位串的特定部分分离出来
1110&0011 = 0010 即分离出了后两位
按位与运算
or $reg1,$reg2,$reg3
reg1=reg2®3
与立即数进行与运算
ori $reg1,$reg2,immediate
reg1=reg2|immediate
⭐任何数与1做或为1,与0做或为原数—>强制某些位为1
Shift Left Logical 逻辑左移
sll $reg1,$reg2,num
将reg2里的值左移num位放入reg1中
空出来的位填0
和sll类似,不过右移num位
空出来的位填0
Shift Right Arithmetic 算术右移
左移num位就是$ ×2^{num}$
右移$ ×2^{-num}$,或者说$ ÷2^{num}$
📌要做计算的时候记得用sra
简单的嵌套调用可以使用寄存器约定;但是复杂的多层嵌套调用就必须使用栈了!

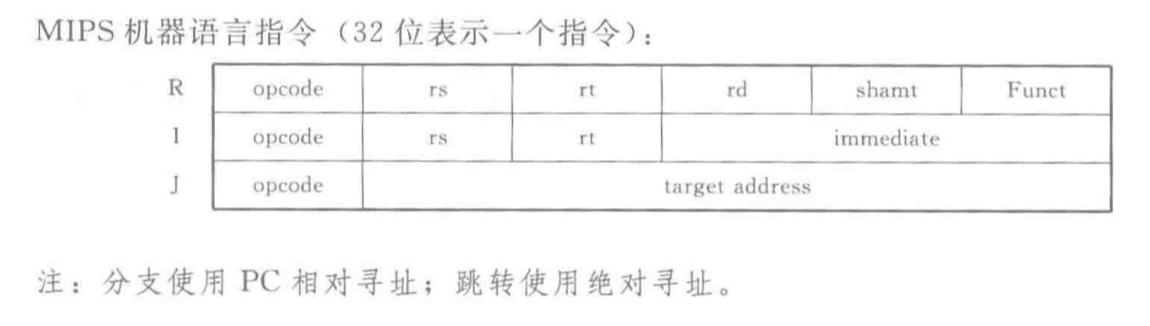
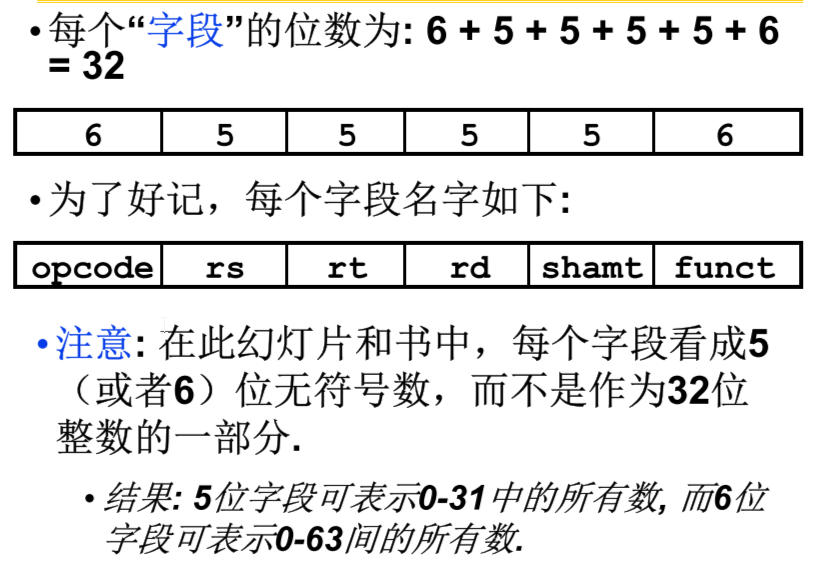
Source Register 确定首操作数的寄存器Target Register 确定次操作数的寄存器Destination Register 指定存放计算结果的寄存器
addi,slti 立即数符号扩展为32位
❓这里无符号数也进行符号位扩展,为了硬件的简单牺牲一定的数据,仅对$2^{15}\le $n$\lt 2^{16}$有问题,只能由汇编器想办法解决了
I格式问题
如何解决I格式问题?软件中处理+新指令
新指令lui register,immediate
Load Upper Immediate 装入立即数高位
取立即数并将立即数放到寄存器高位部分,剩下部分填充0
我们只有16位立即数,怎么解决32位分支指令?
PC-相对寻址作为32位分支指令解决方案
以PC为基点,分支$\pm 2^{15} $字节,保证大多数循环的寻址要求
指令是字,满足字对齐,后两位总是00
这样以PC为基点,可以分支$\pm 2^{15} $个字 (或$\pm 2^{17} $个字节),因此,可以处理的循环范围为原来的4倍

现在可以表示26位的地址
对于32位机器指令的解码遵循下面步骤
不能直接转成MIPS语言,先要转成几条MIPS指令的组合
MAL(MIPS Assembly Language) 包含伪指令
TAL(True Assembly Language) 不包含伪指令
C--->MAL--->TAL翻译顺序
寄存器赋值
move $reg2,$reg1
将reg1的值赋给reg2
装入立即数(Load Immediate)
li $reg,immediate
装入地址(Load Address)
la $reg,label
把label对应的地址装入reg
循环右移(Rotate Right Instruction)
ror $reg,value
把寄存器中的值循环右移value位
比如addu指令写成了addu $reg1,$reg2,immediate
会自动改写为addiu $reg1,$reg2,immediate
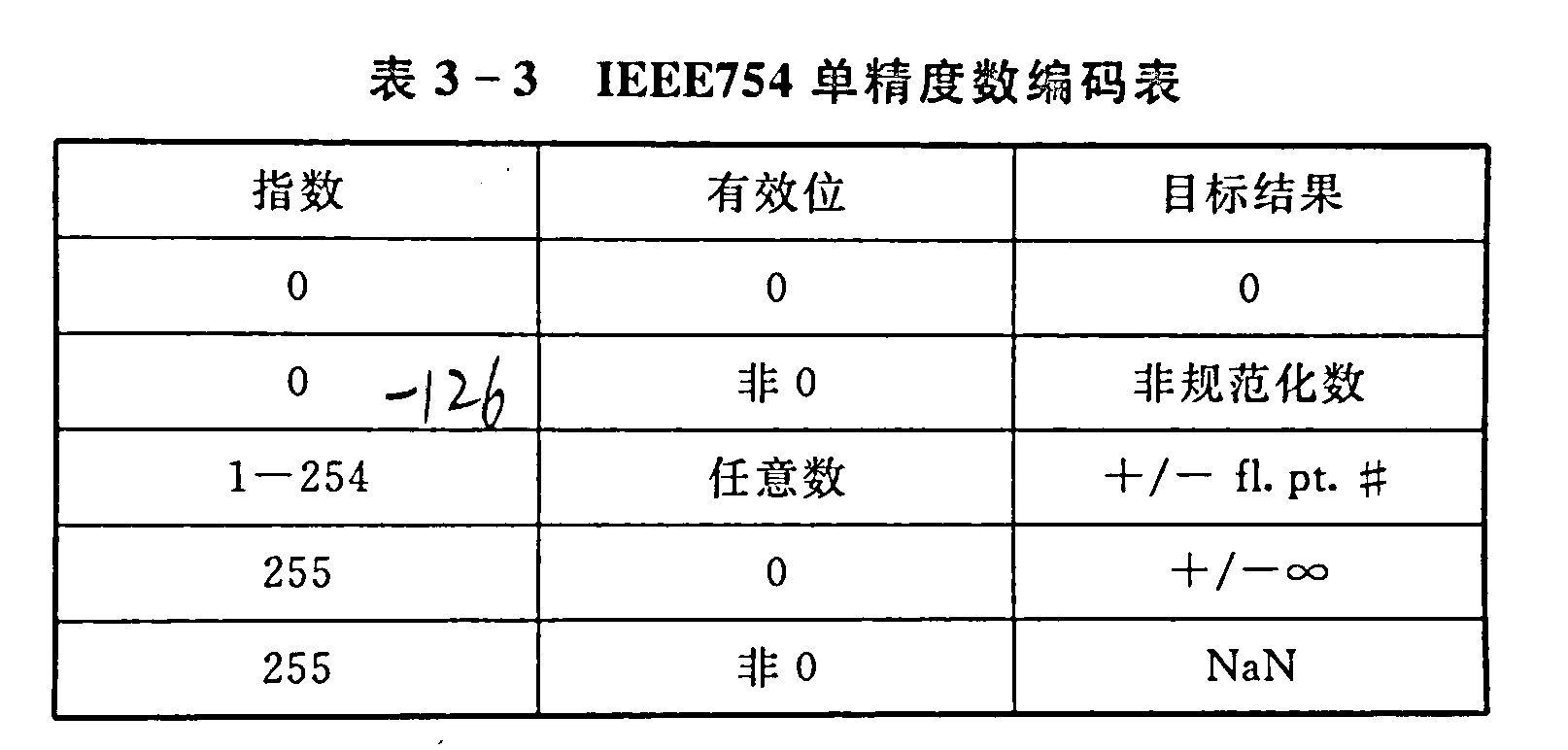
IEEE754标准
标准形式

通过一个例子感受如何在二进制位串和十进制数字间进行转换
0 |0110 1000|101 0101 0100 0011 0100 0010
将上面的位串转换为十进制
十进制转二进制

精度
精确性
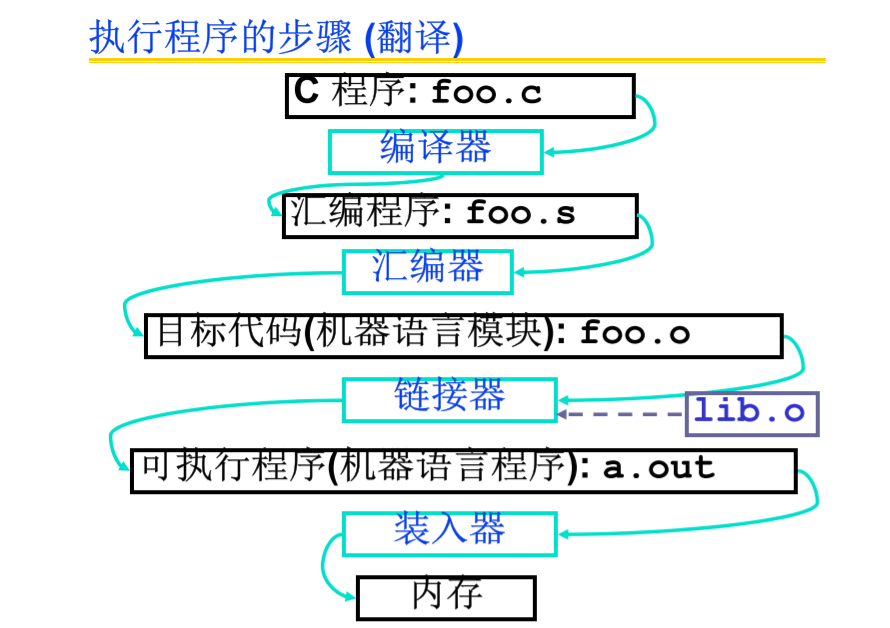
高级语言的执行有两种方式
指示器产生一系列的提示信息,不产生机器指令
将伪指令替换为一组汇编指令
分支怎么办?PC相对寻址
前向引用问题?分支指令引用还未遇到的标记
使用两次扫描的方式解决问题,一次扫描记住标记位置,第二次扫描使用标记位置产生代码。
跳转指令的问题?需要绝对地址
产生两张表
输入代码和信息表;输出可执行程序
使得多个文件的分离编译称为可能
动态链接库DLL
便于及时更新,且体积小
静态链接库lib
操作系统的一部分,输入执行代码(.out).exe,输出正在运行的程序
ISA(Instruction Structure Architecture,指令集结构)是软件与硬件之间的协议
晶体管的两种类型
同步数字系统由两种基本电路构成
信号正边沿触发!
状态单元用来储存数值,控制组合逻辑块间的信息流动;如寄存器
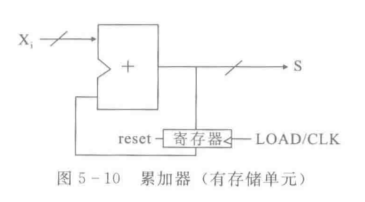
寄存器由多个翻转器(在0,1之间变换)组成,正边沿触发;reset是强制清零的信号
可以通过增加寄存器加快时钟频率
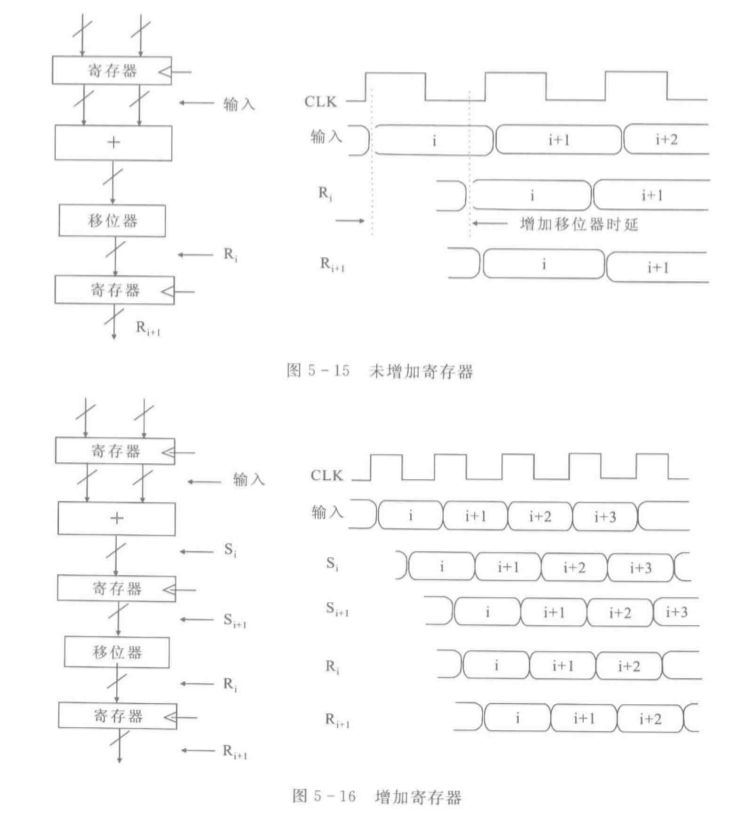
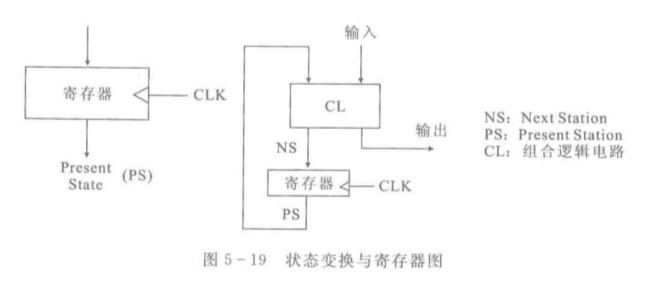
状态变换FSM图也可以借助寄存器来实现
常见逻辑门的表示与真值表
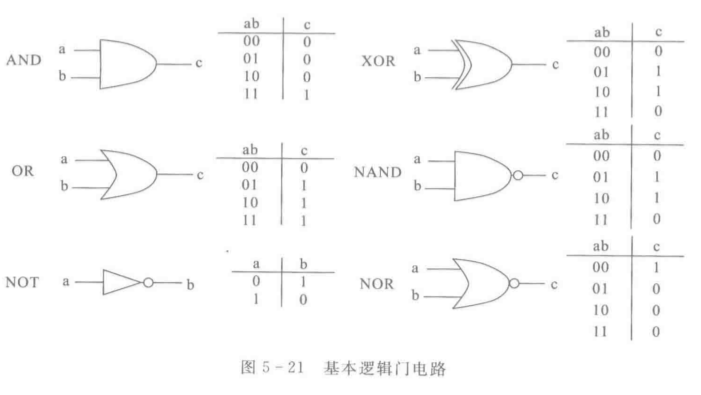
异或XOR:当有奇数个1时输出1
运用布尔代数可以化简电路
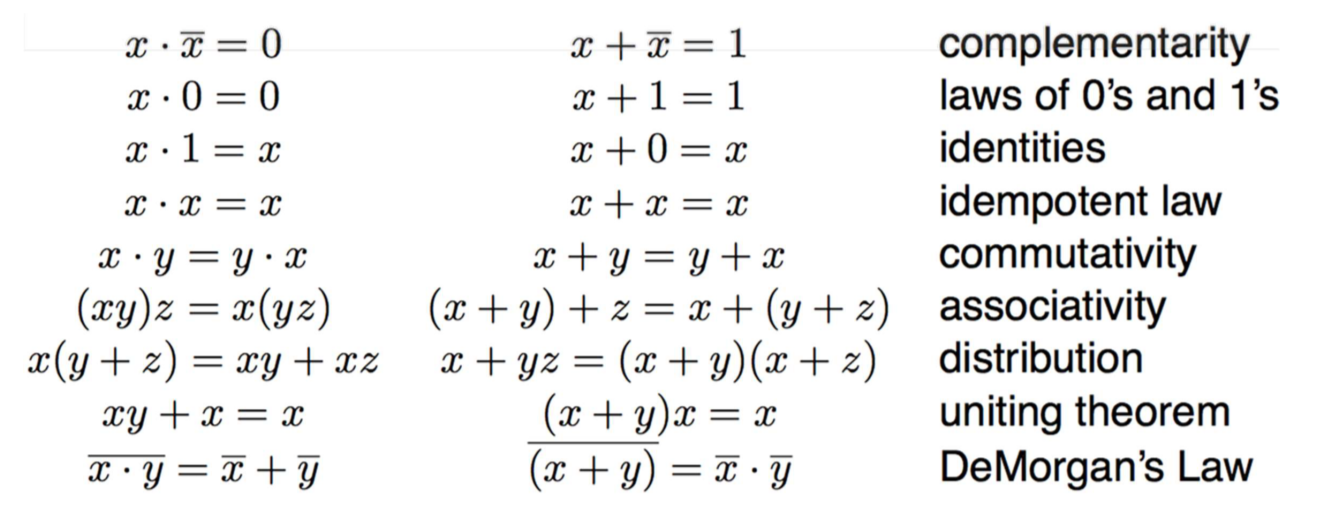
结合真值表可以设计电路
如何从真值表生成门电路呢?看下图
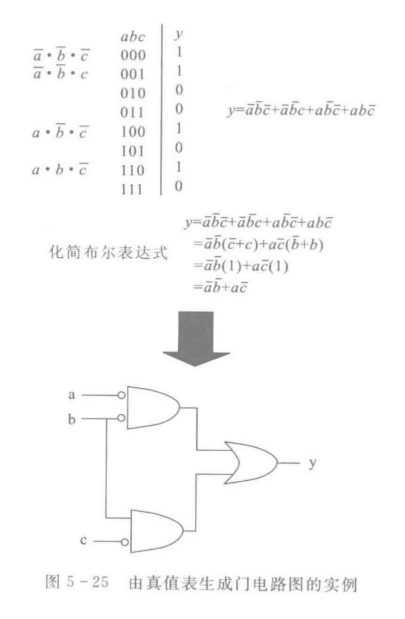
·是And
+是Or
图5-25中显示的是二选一MUX;利用层次结构可用二选一的MUX组合成四选一的MUX
32位加法器
首先画出真值表,发现有$2^{64}$个表项;太多了,我们得换个思路—->分解!
设计一位加法器
画出真值表—>写出布尔表达式并化简—>设计电路
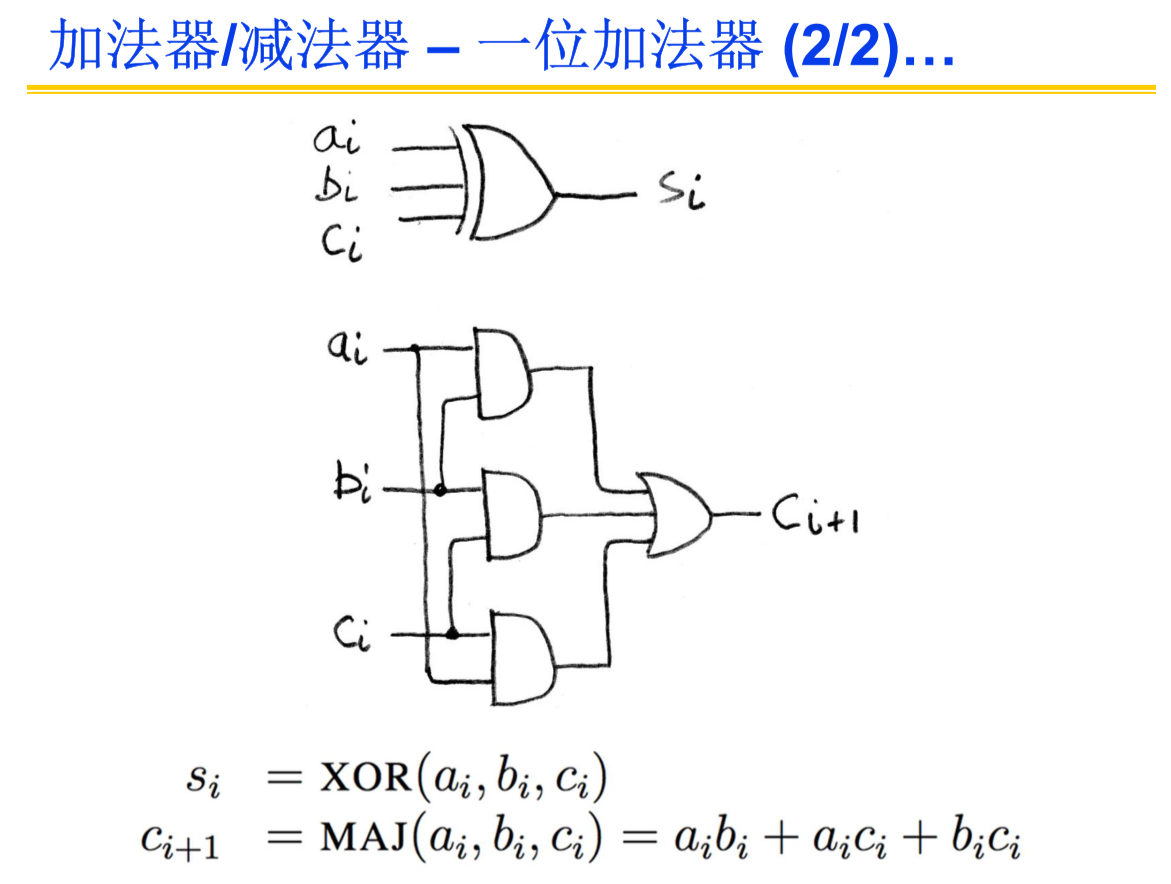
把许多一位加法器连起来就可以构成多位加法器
溢出?不懂
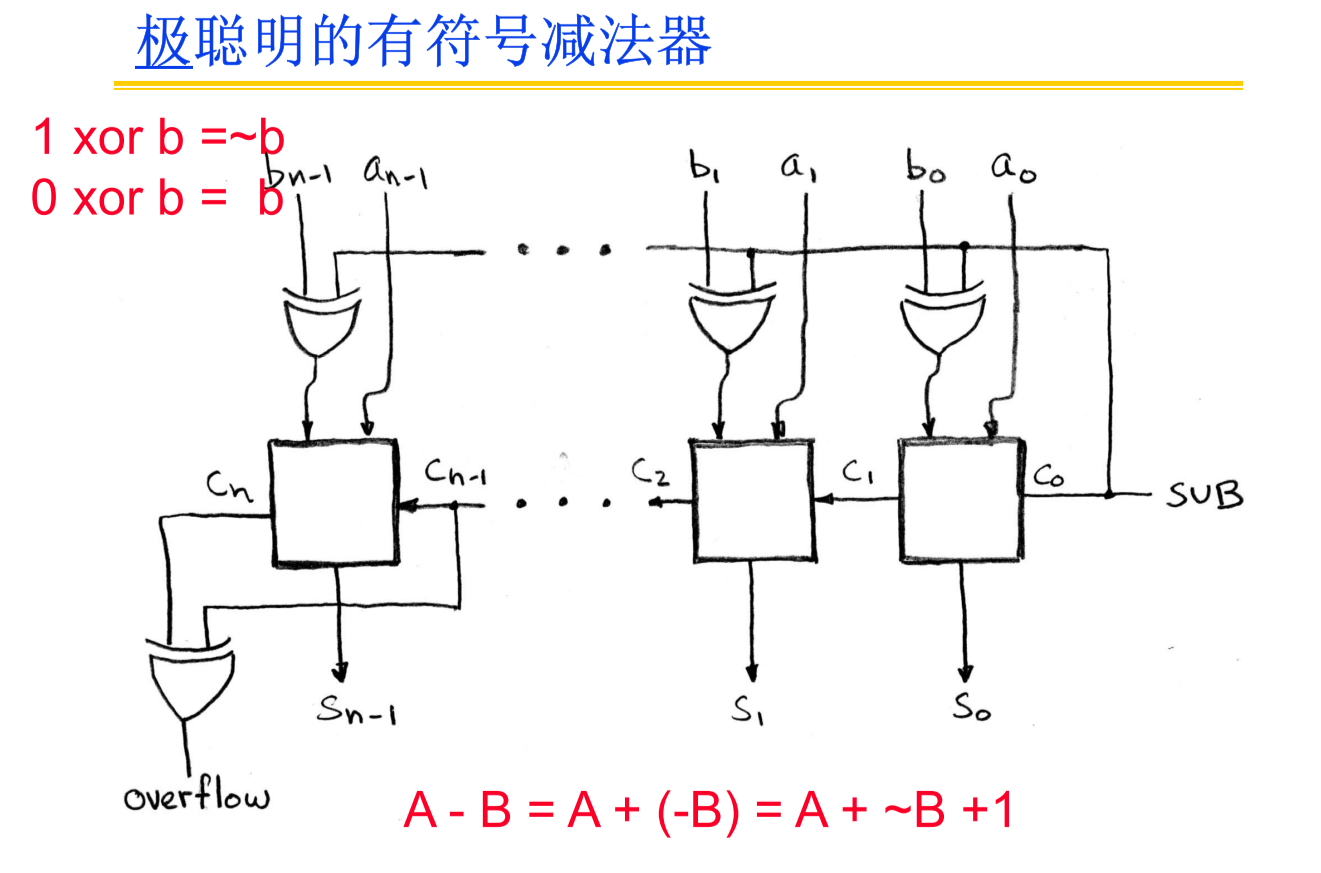
减法器实际上只需要在加法器上做一点点改进就好
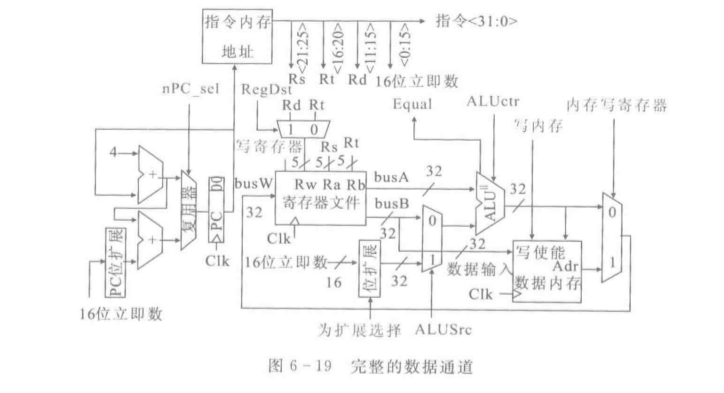
数据通道分为五步
需要在脑海里能够画出下面这个完整版的数据通道
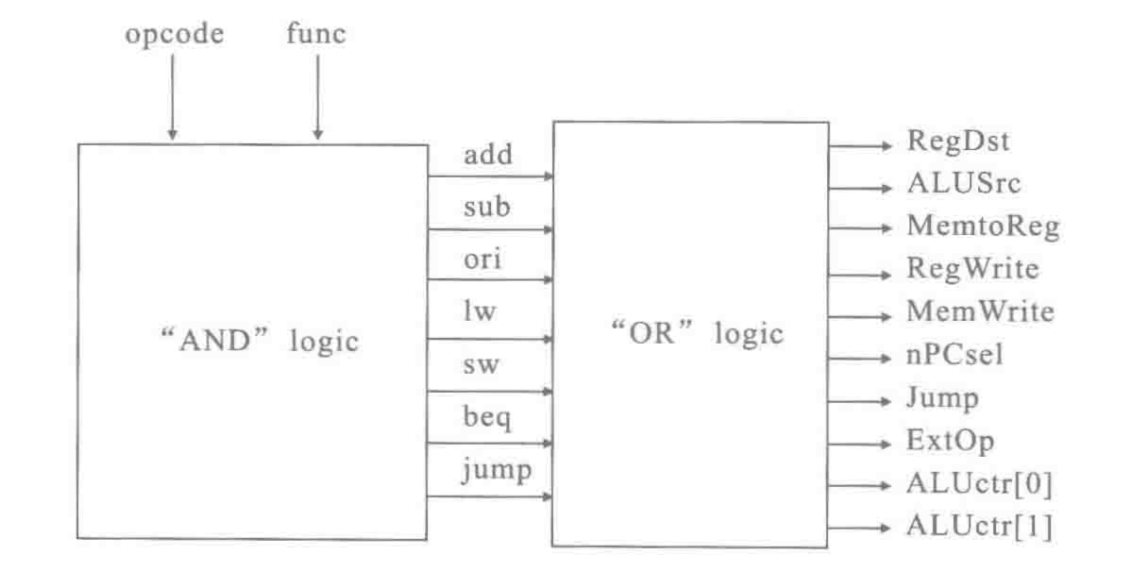
控制信号的设计,其实就是opcode与funct做and运算,得到一串二进制数,这串二进制数做or运算得到所需的信号
延迟不变;增加吞吐量
硬件不支持某些组合
要等分支语句的判断出来后才能进行下一步
后方指令依赖前面指令的结果
利用时间局部性和空间局部性
Cache是主存的子集的一个拷贝
Cache与内存间传输数据的单位——块block
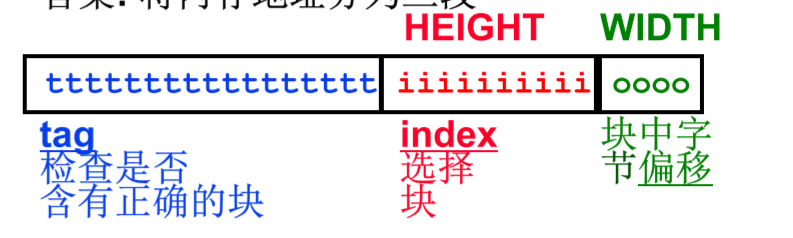
如上图,内存地址被划分为三块tag index offset
offset长度根据(能表示一个块包含的字节数来决定的位数)
index长度等于(能表示(缓存大小÷一行缓存的大小)这个的位数)
tag = 地址位数-offset和index的位数
访问cache有三种情况
访问cache有这样三步
更新内存的方法
写内存Write Through
写回WriteBack
最小化平均访问时间AMAT(Average Memory Access Time)
AMAT=$HitTime+MissPenalty×MissRate$
块替换策略,常用LRU
]]>太久不更新了,果然人类的本质就是鸽子吗
今天结束了数据库的上机,晚上不想写报告,开始折腾起来虚拟机了;起因是我之前写了篇虚拟机安装MacOS的文章👉链接;但是安装上之后屏幕显示分辨率一直不正常,而且也没办法用代理链接Github,这就非常的没用了。今天折腾了一下,把问题解决了,写篇博客记录一下🖖
——某位马上要考六级期末一堆DDL的摸鱼大学生
一般来说,在虚拟机内部设置代理有这么几个办法:
那么我就介绍第二种办法,要优雅XD
打开虚拟网络编辑器
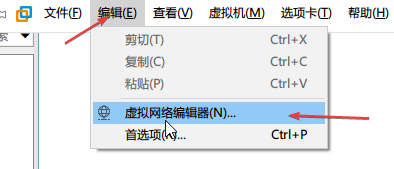
点击更改设置
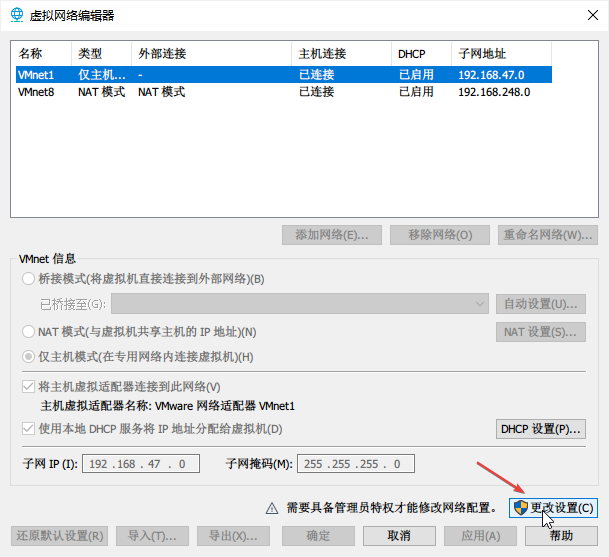
如图所示加上VMnet8,并配置相关参数。
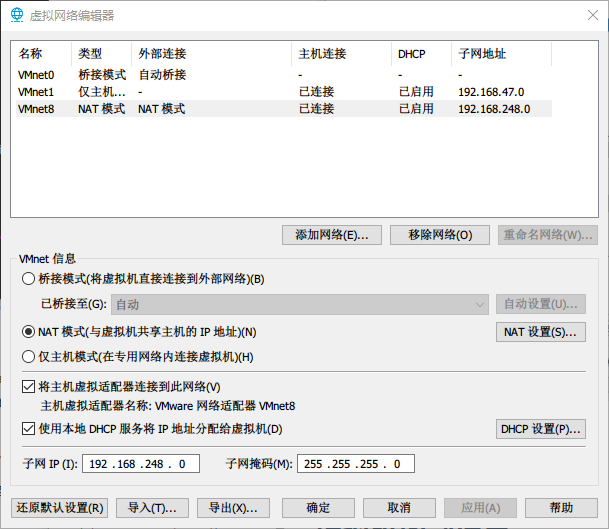
接下来就对单独的虚拟机进行设置
更改网络设置
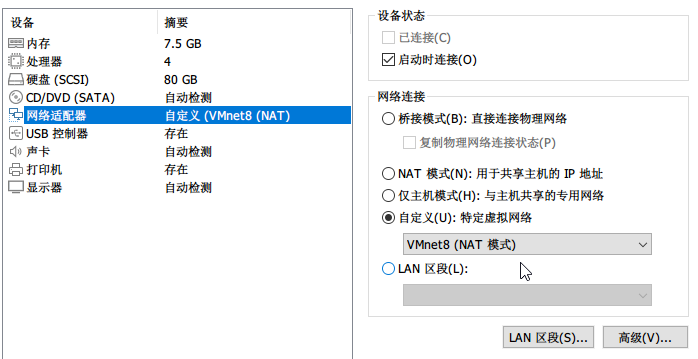
到这里,只需要再获取VMnet8的ip地址就好;打开CMD,输入ipconfig找到VMnet8
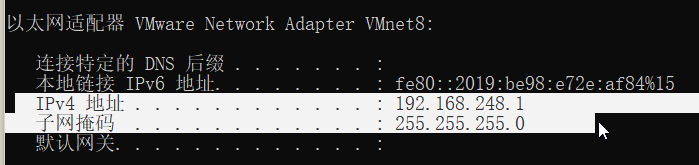
打开你的虚拟机,这里用MacOS做演示;Ubuntu操作见链接
进入你的Mac虚拟机,打开设置里的网络选项,点击高级进入下图页面;请将我勾选的四项都设置为上面让你记住的ip地址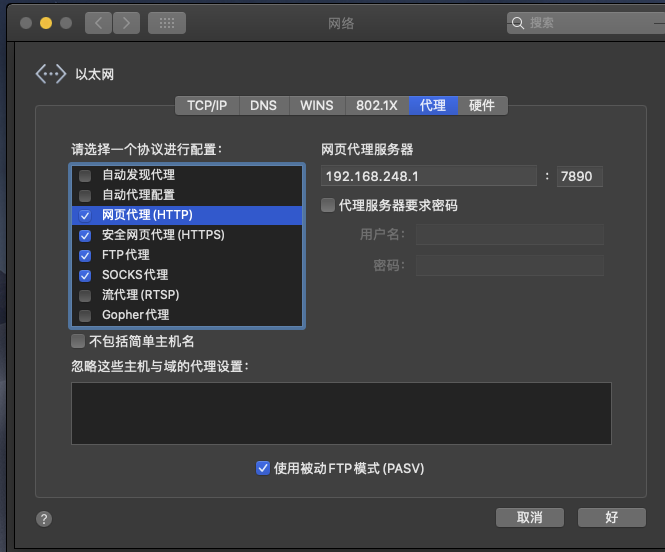
端口号和你的代理软件相关,我这里使用的是Clash,端口就是上面那个箭头所指的位置;记得一定把Allow LAN打开,因为VMnet8走的就是LAN(Local Area Network)
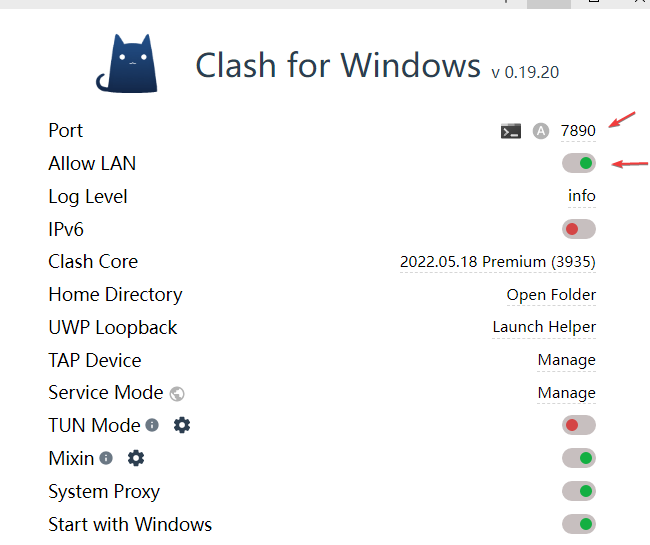
以上,代理设置完毕!愉快地使用 Github 吧!
在你按照我之前的教程安装完MacOS后一定会发现,这个分辨率怎么这么糊啊,而且还改不了,就很难受🤦♂️
下面我们着手解决这个问题
打开MacOS后,点击菜单栏里的虚拟机再点击安装VMware Tool,按照提示进行安装就行,详情请看👉链接
具体步骤
打开首选项
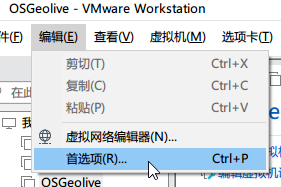
如图进行设置
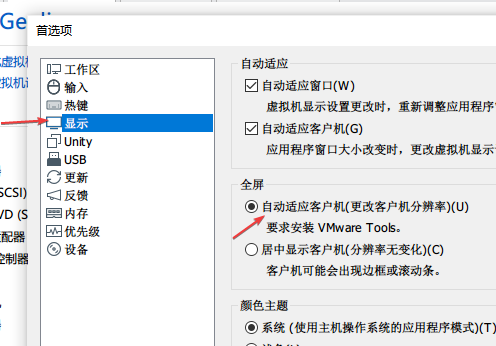
设置完后重启MacOS
点一下自由拉伸,然后随便拉伸一下虚拟机的窗口
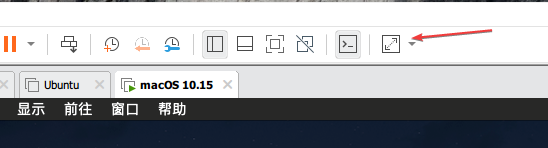
如果这样还没有用,就打开Terminal
输入/Library/Application\Support/VMware\ Tools/vmware-resolutionSet 1920 1080
之后再在设置里改一下显示比例
这个方法我没有使用,如果有问题可以参考👉链接
https://www.zhihu.com/question/68703160
https://blog.51cto.com/sddai/3090254
https://www.jianshu.com/p/4384047334d1
https://www.geekrar.com/how-to-fix-macos-catalina-screen-resolution-on-vmware/
]]>I/O 设备可以分为:
Block Device
如磁盘512 Bytes-->32768 BytesCharacter Device
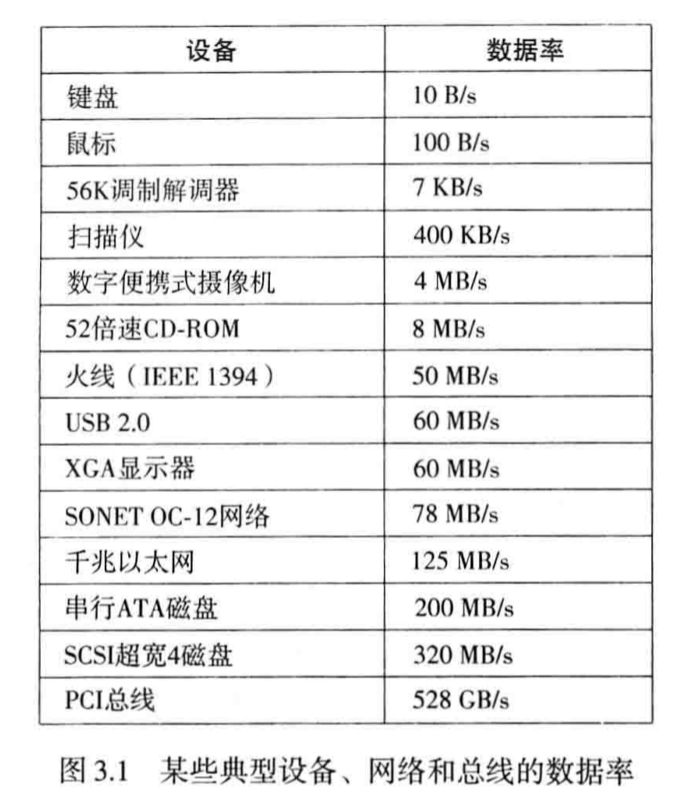
打印机、键盘、网络接口、鼠标等时钟❗ I/O 设备在速度上差异很大,见下图,这为我们管理 I/O 设备提出了挑战,在后文中会提到解决办法。
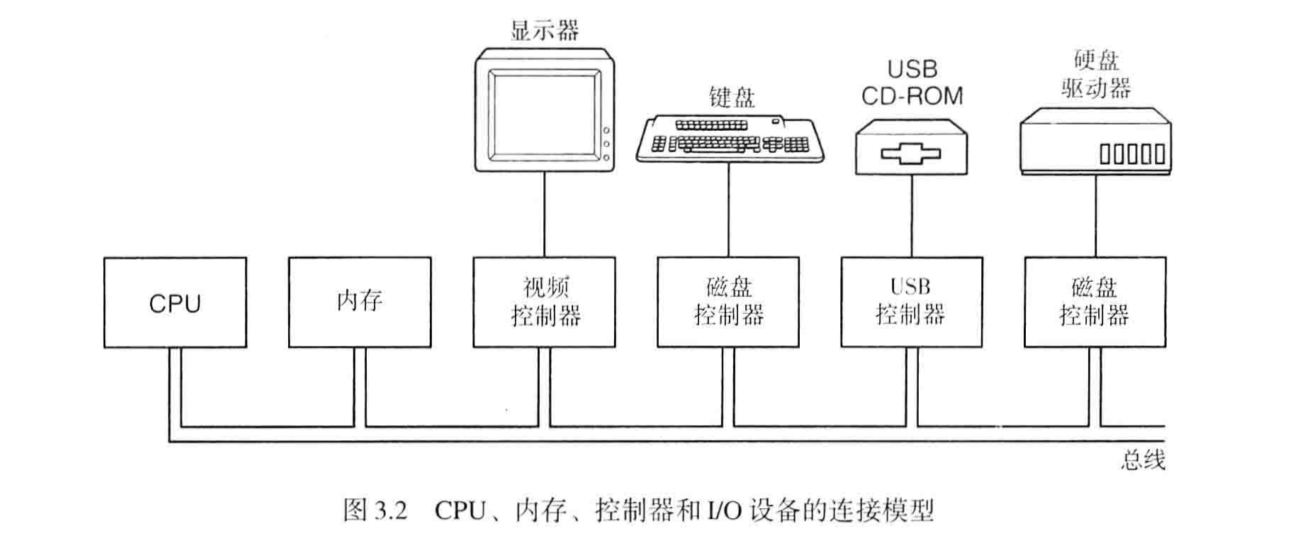
I/O设备组成中的电子部件被称为设备控制器,操作系统往往和设备的控制器打交道,大多数个人计算机采用总线模型进行 CPU 与控制器之间的交流。
大型机则采用其他模型,此类模型带有I/O通道,一种专用于输入输出工作的计算机。
❓ CPU如何控制寄存器与设备数据缓冲区进行通信?
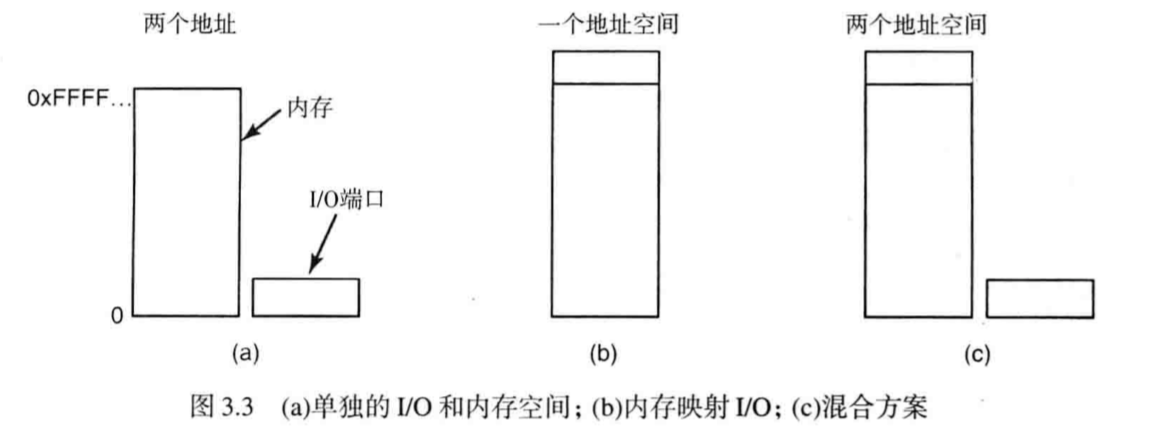
大部分I/O接口提供一个输出用于驱动IRQ Interrupt ReQuest线
即插即用技术使得 BIOS 在启动时为设备自动分配 IRQ 以避免冲突
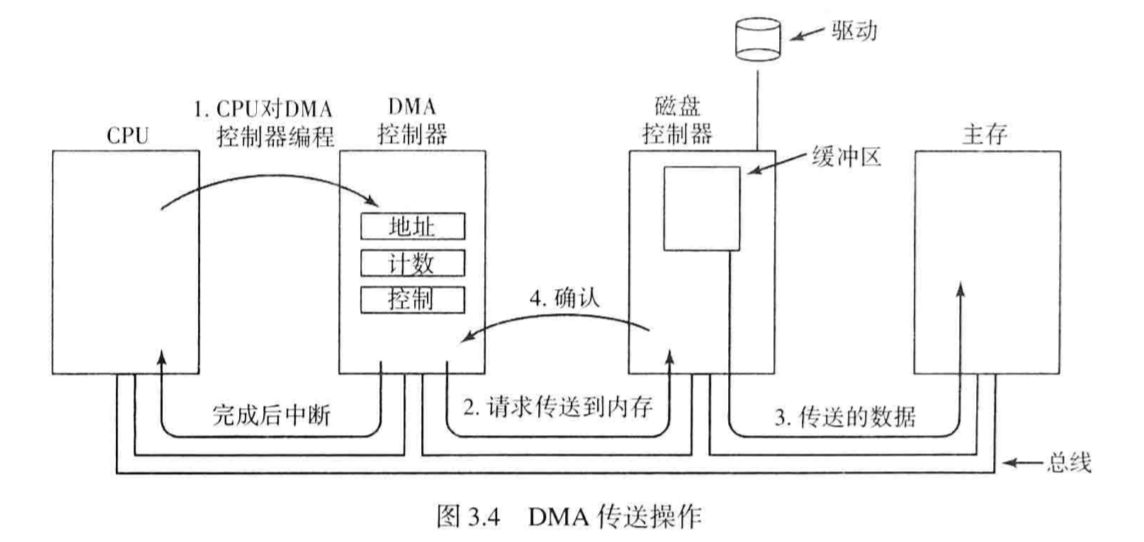
Direct Memory Access , DMA
它使得毋须占用CPU宝贵的时间去交换数据,利用 DMA 控制器调控多个设备的数据传送
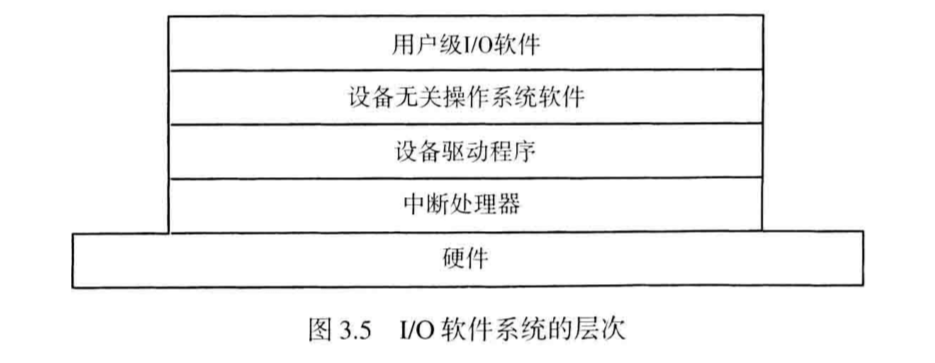
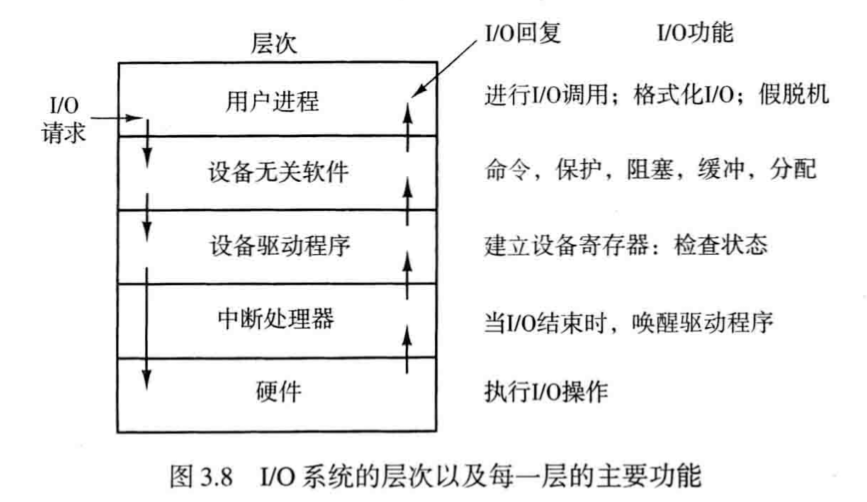
用来控制特定设备的一组特定的代码被称作设备驱动程序,驱动程序传统上是系统内核的一部分
一个进程集合中的每个进程都在等待本集合中其他进程才能引发的事件,那么这组进程是死锁的
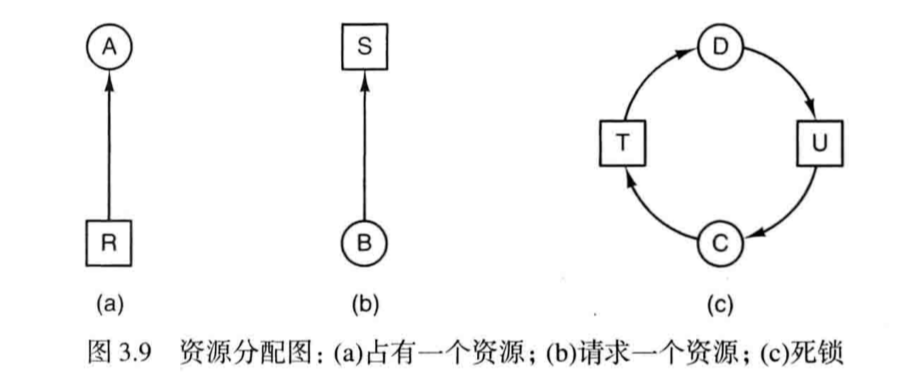

<font color=red size=4.5 face=仿宋>通过仔细分配资源来避免死锁</font>
在进程申请资源的时候,判断本次申请是否安全,如果安全再分配,就像银行借贷款。
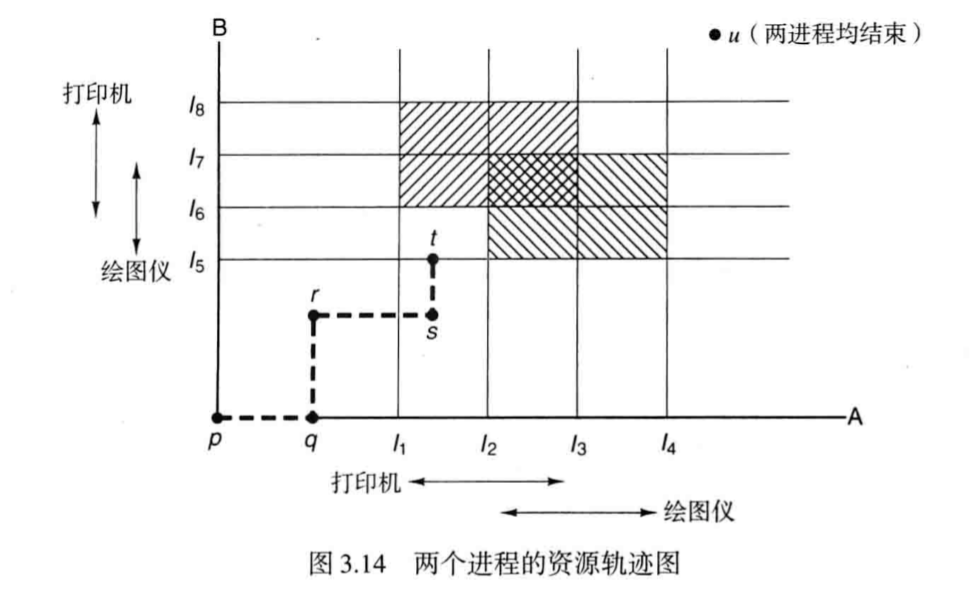
上图中,阴影区域内就是资源发生冲突的区域
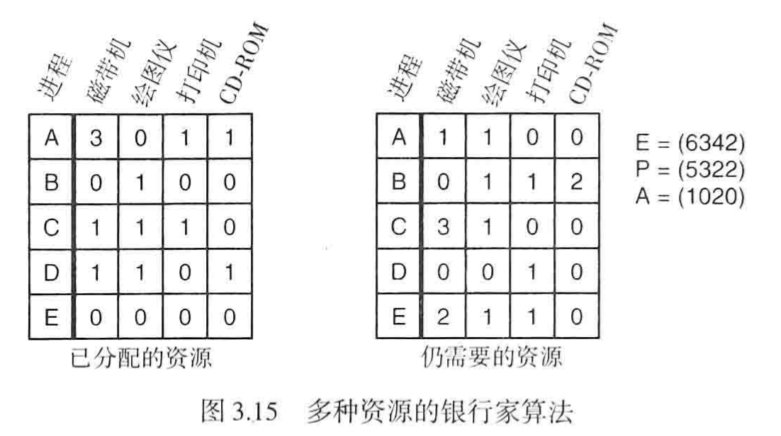
算法详情:
]]>📌事实上,银行家算法虽然很有意义,但缺乏实用价值,因为很少有进程能在运行前知道自己所需资源的最大值!